


Ref: z2511081m
(Information provided by Systems 104 Technology, tel 012 346 5437, [email protected])
As consumer demand grows for driver information systems (DISs), competition will force auto manufacturers to add more applications and more network services, in progressively shorter time frames. To complicate matters, much of the software (eg browsers, e-mail clients) deployed in DIS products may have to be updated on a regular basis to avoid obsolescence. Unfortunately, most embedded operating systems (OSs) are not equipped to handle this 'feature race'. The underlying problem? OS architecture. Conventional embedded OS architectures provide either no support, or limited support, for the memory management unit (MMU).
As a result, the complex system software for something like a DIS can require extensive debugging and testing for even minor code enhancements. In this paper, we compare architectures and see how one approach, Universal Process Model (UPM(tm)) architecture, helps developers redirect their efforts away from verification and maintenance and back toward innovation - and faster development cycles. Unlike other OS architectures, UPM allows drivers and OS modules, not just applications, to run in their own MMU-protected address spaces. This not only eliminates needless testing, but also boosts reliability. For example, UPM can enable a DIS to recover from software faults, without rebooting. UPM also helps eliminate software obsolescence, since any new or updated software component, even an OS module, can be dynamically downloaded and started - again without forcing the DIS to be rebooted.
Feature race: The competitive reality of in-car computing
As consumer demand grows for driver information systems, one thing is inevitable: competition will force auto manufacturers to deliver systems with more and more features - and to introduce those features in ever shorter time frames. You can see this same 'feature race' occurring in other information appliances, from PDAs to set-top boxes. Driver information systems with their promise to combine navigation, speech recognition, wireless communications, web access, e-commerce, and other online services are no exception.
Unfortunately, this means that auto manufacturers and systems providers will soon discover the same problem as designers of other information appliances: that most operating systems (OSs) are ill equipped to handle the whirlwind demand for new features. The problem springs from traditional embedded design, where software often remained stable, with little or no change, over a product's entire life cycle. Most OSs, having been created for such products, still reflect the old reality.
What does this mean? New software features cannot simply be 'plugged in' or upgraded in an existing system. Rather, most or all of the system software stack must be rebuilt and carefully retested for even small enhancements. This not only puts the brakes on developing new features quickly, but also means that independent software vendors (ISVs) cannot readily offer value-enhancing applications for an existing in-car system; the system is, in effect, 'closed'. It also means that installed systems cannot easily be maintained, upgraded, or extended. And that is a problem, since features like web access may have to be upgraded frequently (with XML, multimedia plug-ins, and so on) if a customer's in-car system is not to become obsolete just months after purchase.
Flat OS architecture: A development bottleneck
To understand these issues, and how they can be solved, let us look at the traditional 'flat' architecture still used by the huge majority of homegrown and commercial embedded OSs. As shown in Figure 1, this architecture folds all software modules into the same address space as the OS kernel; there is no memory protection whatsoever. As a result, any module, no matter how trivial, can overwrite memory used by the kernel and crash the entire system. All it takes is a single programming error, like an invalid C pointer.
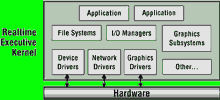
Obviously, this architecture leaves little room for error. Which is not a problem for a simple design, where most problems can be tracked down during integration testing. But what happens when a driver information system grows to integrate a variety of sophisticated applications - navigation, diagnostics, cell phone, natural speech processing, wireless web access, and so on - requiring 500, 1000, or more modules? With thousands of lines of code and perhaps hundreds of active execution threads? If a stray pointer crashes the system, where do you start looking? Even the best debugging tools may not identify which module was at fault. And since no one person can understand the entire code base, even experienced kernel programmers can take days, weeks, sometimes months to reproduce the problem and locate the bug.
Extensive retesting
Now let us say you have fixed the bug, or perhaps added a minor feature. Chances are, you will have to retest your entire software suite. The reason is simple: every time you make a code change under a flat architecture, you have to relink the entire runtime image, which creates a new image with different memory-address offsets. As a result, any module that had been overwriting an unused data area may now overwrite a critical data area used by another module or even the OS kernel. This problem, among other things, effectively prohibits third parties from reliably offering applications for your system.
Reduced prototyping
Flat architecture also limits your ability to try out new design ideas. For instance, every time you change code, you have to rebuild the runtime image. And every rebuild can, in more complex applications, take several hours. As a result, prototyping even a minor feature can be time-consuming.
The performance myth
With a flat architecture, bugs can take so long to locate that you can end up spending significantly more time on QA and maintenance than on developing new features or products. Why, then, do some embedded OSs continue to use flat architecture? One reason is historical. In the past, most embedded processors lacked an integrated memory management unit (MMU). Another reason is performance.
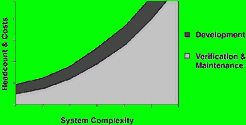
Many commercial and inhouse OS developers find it difficult to support the additional overhead of the MMU. In fact, some claim that, for the sake of performance, memory protection must be sacrificed. As it turns out, this is not necessarily true. As we will discuss later, not only can a well-designed OS provide extensive MMU protection, it can also deliver performance equal to, or exceeding, that of a conventional, flat architecture OS.
Monolithic architecture: Meeting the problem halfway
In an attempt to address the problems of flat architecture, a few OS vendors have adopted a monolithic kernel architecture; see Figure 3. In this architecture, every application module runs in its own memory-protected address space. If an application tries to overwrite memory used by another module, the MMU will trap the fault, allowing the developer to identify where the error occurred.
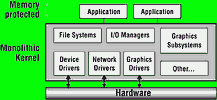
At first glance, this looks good. The developer no longer has to follow blind alleys, looking for subtle bugs in application code. But there is a catch. All low-level modules - file systems, protocol stacks, drivers, and so on - remain linked to the same address space as the kernel. A single memory violation in just one driver can still crash the system, leaving little or no trace of the error. That is a problem, since embedded developers spend much of their time developing low-level components.
As a result, the problems associated with flat architecture remain: days or weeks hunting down corrupt C pointers, extensive retesting for every code change, and the potential for even a trivial module to bring down the system.
UPM architecture: The bug stops here
To eliminate the development bottlenecks we have described, and to ensure the reliability that a DIS requires, an OS has to implement Universal Process Model (UPM) architecture:
As shown in Figure 4, UPM architecture implements a small set of core services within the kernel itself - such as scheduling, IPC, and initial handling of interrupts. All other system services are provided through optional, add-on processes. As a result, every driver, protocol, file system, I/O manager, and graphics subsystem can run in its own memory-protected address space.
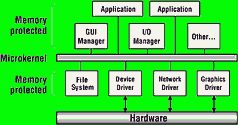
Right away, you can see that this architecture boosts reliability. First, the OS kernel contains very little code that could go wrong. Second, it is highly unlikely that any module - even a poorly written driver running at the highest privilege level - can corrupt the kernel.
Better yet, every module now runs as an independent process, which means you can start, stop, modify, or upgrade any part of your software system dynamically, without a reboot or kernel rebuild. Let us see how that translates into significantly higher availability at run time - and results in higher productivity at development time.1
Advantages at run time
UPM virtually eliminates kernel faults. But it has a number of other inherent features that can also boost the reliability and availability of driver information systems. These include automatic recovery from software errors, hot-swapping of both hardware and software, and the ability to distribute components of your application across multiple CPUs.
Increased fault tolerance
No matter how thorough you are, some bugs will go undetected until they show up at run time. With a flat architecture, a reboot is the only way to recover. With a monolithic architecture, you could recover without a reboot, but only if the fault is at the application level. With UPM, however, you can recover without a reboot even if a fault occurs in a driver, protocol stack, or custom OS module. To do this, you can use intelligent mechanisms called software watchdogs.
For example, let us say a driver fails. Instead of forcing a full reset, a software watchdog could:
* simply restart the driver
OR
* restart the driver plus any related processes.
In either case, the software designer can determine exactly which processes will be restarted.
Postmortem analysis
While performing a partial restart or, if necessary, a coordinated system reset, the software watchdog can also collect information about the software failure. For example, if the system has access to mass storage (eg flash memory, hard drive, a network link to another system with a hard drive), the watchdog can generate a process dump file that you can view with source-level debugging tools. This dump file:
* Identifies the exact line of code that caused the fault.
* Allows you to view resources such as variables and a history of function calls/
Compare this approach to conventional hardware watchdogs - which simply reset the system without leaving a trace of what went wrong - and the choice is clear. Instead of being at a loss to explain what happened, you can actually work on fixing the problem.
Better still, a software watchdog can monitor system events that may be 'invisible' to a hardware watchdog. For example, a hardware watchdog can ensure that a driver is servicing the hardware, but may have a hard time knowing whether other programs are talking to that driver correctly. A software watchdog can cover this hole, and take action before the driver itself shows any problems.
Dynamic software upgrades
Of course, bugs are not the only thing that can bring a driver information system to a stop. For example, let us say the system needs to download a new or updated application via a wireless link. With most embedded OSs, the system would, at the very least, have to be rebooted for the new program to work. With UPM architecture, however, almost any module - even a driver or protocol stack - can be upgraded dynamically. No need for a reboot or for any effort on the part of the customer. Automotive OEMs can, as a result, continue to add revenue-generating services long after the system has been installed in a vehicle. (Note that a few monolithic OSs provide somewhat similar functionality, by allowing you to dynamically attach drivers to the kernel. But because these drivers then run in kernel space, they cannot be removed, restarted, or dynamically replaced with new software. In contrast, UPM allows almost any component to be added, removed, or upgraded as needed.)
Scalability through distributed processing
One of the best ways to improve reliability is to distribute components of your application across multiple CPUs. That way, even a CPU failure will not stop the application from providing service. For instance, if a CPU went down, the remaining CPUs could take over all or some of its duties until it was replaced or restarted.
In fact, as an application grows, you often have no choice but to divide it across two or more CPUs. Not because of reliability (though that may be a factor), but because the application requires more physical interfaces, or simply more processing power, than one CPU can handle.
Unfortunately, conventional embedded OS architectures can make this an awkward task, since most or all software modules are bound to the kernel. For example, if you move a protocol stack from one CPU to another, you may have to create, and carefully test, two new kernel images - one for each CPU. And if the OS does not provide a transparent means of talking to a module moved to another CPU, then you will have to recode both the module itself and the modules it communicates with. As a further complication, it is often difficult to determine which processes should be assigned to which CPU. You may not know until the integration phase that you have chosen to distribute processes in a way that fails to provide optimal performance. At which point it may be too late to recode, rebuild, and retest your software.
UPM sidesteps these problems by decoupling everything from the kernel - every software module is an independent, movable object. And if UPM is implemented so that interprocess communication (IPC) travels transparently across the network, then one process can continue talking to another process even if one of them is moved to another CPU. No code changes or relinking required. In fact, the exact binary of any process can be relocated at any time, even at run time.
This means, of course, that programmers do not have to code with a specific system configuration in mind. No matter how much the final system is scaled up or scaled down, programmers can write their programs just one way. It does not matter, for example, whether a Flash memory and its associated driver will eventually be located on the local machine or on a remote, network-connected machine. Either way, any process (provided it has the appropriate authority) will be able to access the resource transparently, without special code.
But what about performance?
It is clear that UPM can provide a driver information system with much higher reliability and availability. Nevertheless, a question remains: Does placing each application, driver, and OS module in its own MMU segment impede performance? The answer is no, not if UPM is implemented correctly.
For example, a UPM operating system like the QNX realtime platform can perform a context switch-the time it takes to stop running one process and to start running another-in just 0,62 µsec on a G4 processor. That is more than enough for virtually any high-performance application.2
Advantages at development time
To appreciate the productivity benefits of UPM, let us start with how embedded developers spend much of their time writing custom device drivers. With flat or monolithic OS architecture, all driver code is bound to the kernel. So, every time you test changes to a driver, you have to rebuild the OS image or at the very least reboot. Then, if the driver commits a memory violation, the system can crash without leaving a trace of what went wrong.
Now compare this to UPM architecture, where each driver runs as a separate, memory-protected process. If you change a driver, you simply recompile it, which can take a matter of seconds. No kernel rebuild or system reboot required. And if a memory violation occurs, the OS can immediately identify the module responsible, at the exact instruction. So, rather than waste days or weeks tracking down the problem, you can spend minutes solving it. And to debug the driver - or virtually any other traditional kernel module - you can use the same, standard source-level tools used for debugging regular applications. No need for kernel debuggers or expensive kernel 'gurus'. Writing a driver or a custom OS extension can become as easy as writing a standard application.
Re-using software and reducing verification
As discussed, a single code fix to a driver under a conventional OS can result in a different kernel image-and extensive retesting. With UPM, however, the kernel contains only core services, so you can re-use the same kernel binary that has been lab-tested by the OS vendor and field-tested by every other user. Better yet, every module has a linear virtual address space that starts at 0, so you can also reuse the binary image of every unmodified application, driver, OS module, and protocol stack. The result: most code modifications require that you test only the modules or subsystems affected - not the entire system software suite.
With less time needed for testing, you have more opportunity to add new features or to enhance existing ones, even in the later stages of the design cycle. You can also roll out multiple versions of your product more quickly.
Note that some embedded OSs support a limited process model, but do not follow the above approach. Instead of giving each process a virtual address that starts at 0, the OS relies on fixups and offsets to position processes and drivers in memory. As a result, you cannot always re-use a binary across products. And if you do, you must be careful that the binary fits into the existing memory allocation scheme.
Higher return on R&D resources
With a flat OS architecture, every developer may have to learn how each module works in detail, just to avoid trampling on someone else's address space. As the application becomes more complex, programmers can spend more time learning the source tree than enhancing it.
With UPM, programmers do not have to know the system inside out. If a memory corruption occurs, the OS will identify it. Senior developers are freed up to do what they're paid for: solving core problems and adding real value to products. Meanwhile, new developers become productive much sooner. In fact, since UPM allows low-level modules to be debugged with source-level tools, programmers who have written only user applications can now also write drivers, file systems, and so on.
By the same token, UPM makes it easier to outsource software development, since an independent software vendor (ISV) can contribute code without knowing the source tree intimately. And by providing memory protection between all modules at run time, UPM also makes it less risky to mix the work of outside vendors with code developed inhouse.3
Reclaiming innovation
In summary, OS architecture makes a difference. Not just to system reliability or performance, but to your very ability to create new products under tight deadlines. Of course, good development tools can also make a difference. But as we've seen, tools can't compensate for the significant overhead of debugging, testing, and maintenance imposed by conventional embedded OS architectures.
By eliminating much of that overhead, UPM architecture encourages a 'culture' of innovation. Design teams have more breathing room to add or enhance features, or to create whole new products. Better yet, UPM makes it easier to integrate code developed by ISVs, thus providing one more way to handle shrinking development cycles.
Innovation aside, UPM provides the one other thing automotive applications require: reliability. Unlike systems based on conventional OS architectures, a UPM-based system can recover from software faults and hardware failures, without rebooting. What is more, it allows automotive OEMs to dynamically update drivers, applications, even parts of the OS itself, without removing the system from service or requiring effort on the part of the customer.
Innovation, time-to-market, reliability. Can an OS help with all three? The answer is a definite yes - provided, of course, it has the right architecture.
Notes:
1. Anyone familiar with OS design will recognize UPM as microkernel architecture. However, the term microkernel has been so misused - many OSs claim to have microkernel architecture when they are, in fact, monolithic - that it has lost its original meaning. Worse yet, many people erroneously use microkernel to refer to any OS that is small. Hence UPM.
2. Of course, raw performance alone will not guarantee that the safety critical features of a DIS will always perform in a timely fashion. To ensure these features respond predictably regardless of system load, the OS must provide realtime determinism through mechanisms like nested hardware interrupts, priority inheritance, and preemptive scheduling. A UPM architecture can support these mechanisms, while providing the added security of full memory protection.
3. To make outsourcing feasible, a UPM operating system should support standard APIs, like POSIX, that are already used by large numbers of software developers.
Article supplied by Systems 104 Technology, tel 012 346 5437, [email protected]


© Technews Publishing (Pty) Ltd | All Rights Reserved
 printer friendly version
printer friendly version