


At NXP, we craft our i.MX applications processors and our i.MXX RT crossover microcontroller (MCU) portfolios and families of devices to cover a very wide spectrum of market needs. From verticals needing very low-power dissipation to other end products needing a complex heterogeneous compute platform with multiple CPUs, 2D-3D GPUs, DSPs and NPU machine learning accelerators, our product teams must solve a multi-dimensional optimisation problem. The ultimate goal is to deliver all the compute power and connectivity your application and products need, with minimal unused features so that the area footprint, power dissipation, and cost requirements of the devices are also met.
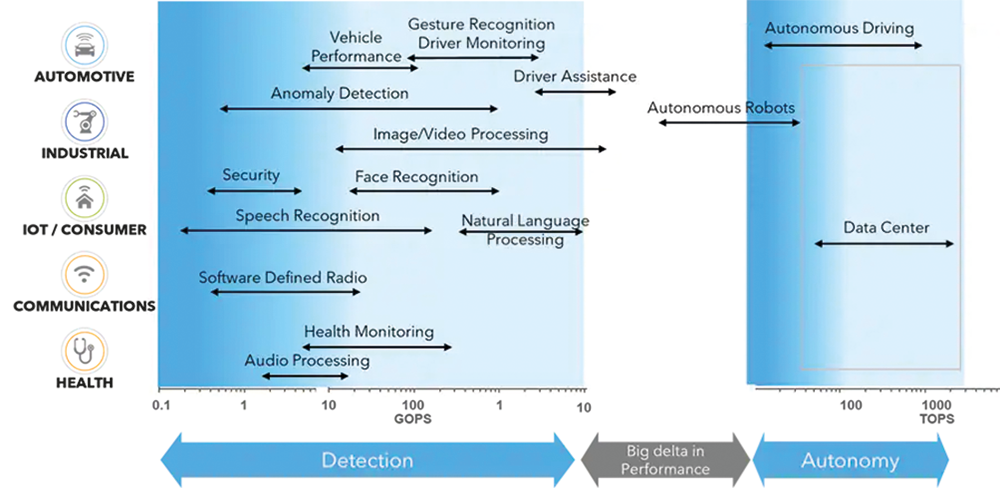 Figure 1 – ML applications and TOPs compute requirements.
Figure 1 – ML applications and TOPs compute requirements.
When talking about machine learning, there are some end uses such as autonomous vehicles and natural language processing that push the compute requirements for edge devices to limits of tens and hundreds of tera operations per second (TOPs). With more emphasis on developing efficient ML models specifically for the edge, and using techniques such as quantisation and pruning, many of the edge machine learning applications fit in the
Giga-Ops to low single digit TOPs range of ML compute performance. NXP solutions natively cover this large portion of AI processing needs.
The software investment dominates the hardware choice these days, especially when considering roadmaps and multiple generation of products. There is a clear benefit to choosing the same or similar applications processor when developing a range of end products, so that the development effort translates to higher maturity and quality, with reuse. Different market segments require different performance on some portion of the application, but the fundamentals remain unchanged between versions and tiers of products. Choosing a scalable processor family such as i.MX applications processors gives the developer flexibility in advanced features and performance range, while simultaneously providing a common base compute architecture and feature set to leverage across both the portfolio and common software enablement elements. NXP provides GStreamer and NNStreamer frameworks to simplify deployment of vision applications with ML.X GStreamer is used as a framework for creating streaming media applications, abstracting the hardware layer to allow the use of any i.MX SoC, without having to change the underlying vision pipeline software.
Application requirements and markets evolve even after a product is launched in the market. So, what does one do when more is still needed from the selected applications processor? Going back to the selection process and looking for a higher performance processor is usually not a preferred option. Adding another device to provide additional acceleration when needed is a possible path, especially with high-speed high bandwidth, low latency chip-to-chip connectivity options such as PCIe. This is where NXP’s ecosystem partners with dedicated ML accelerator chips can help.
Kinara is such an NXP ecosystem partner that develops the Ara-1 Edge AI processors for dedicated ML acceleration. The Gstreamer- and NNStreamer-based vision pipeline support offered by NXP, and the set of Kinara-developed Gstreamer compatible plugins, make it seamless to integrate Ara-1X into NXP inference pipelines and to also easily migrate the design to different i.MXX applications processors if the feature requirements change.
Combining the native MLX processing capabilities of NXP’sX i.MXX applications processors with dedicated MLX accelerators from NXP ecosystem partners such as Kinara, creates an even larger scalability range than that offered by NXP alone while still maintaining software reuse.
| Tel: | +27 11 923 9600 |
| Email: | [email protected] |
| www: | www.altronarrow.com |
| Articles: | More information and articles about Altron Arrow |


© Technews Publishing (Pty) Ltd | All Rights Reserved
 printer friendly version
printer friendly version